Publications and Presentations
Fang, A., Yin, T., , & Kress-Gazit, H. (2024). Continuous Execution of High-Level
Collaborative Tasks for Heterogeneous Robot Teams. arXiv preprint arXiv:2406.18019. (To be submitted to JAAMAS)
Project Details
Safety-critical Control via Lyapunov and Barrier Functions
Group
Advised by Prof. Sarah Dean
Certified Control, Data-driven Control
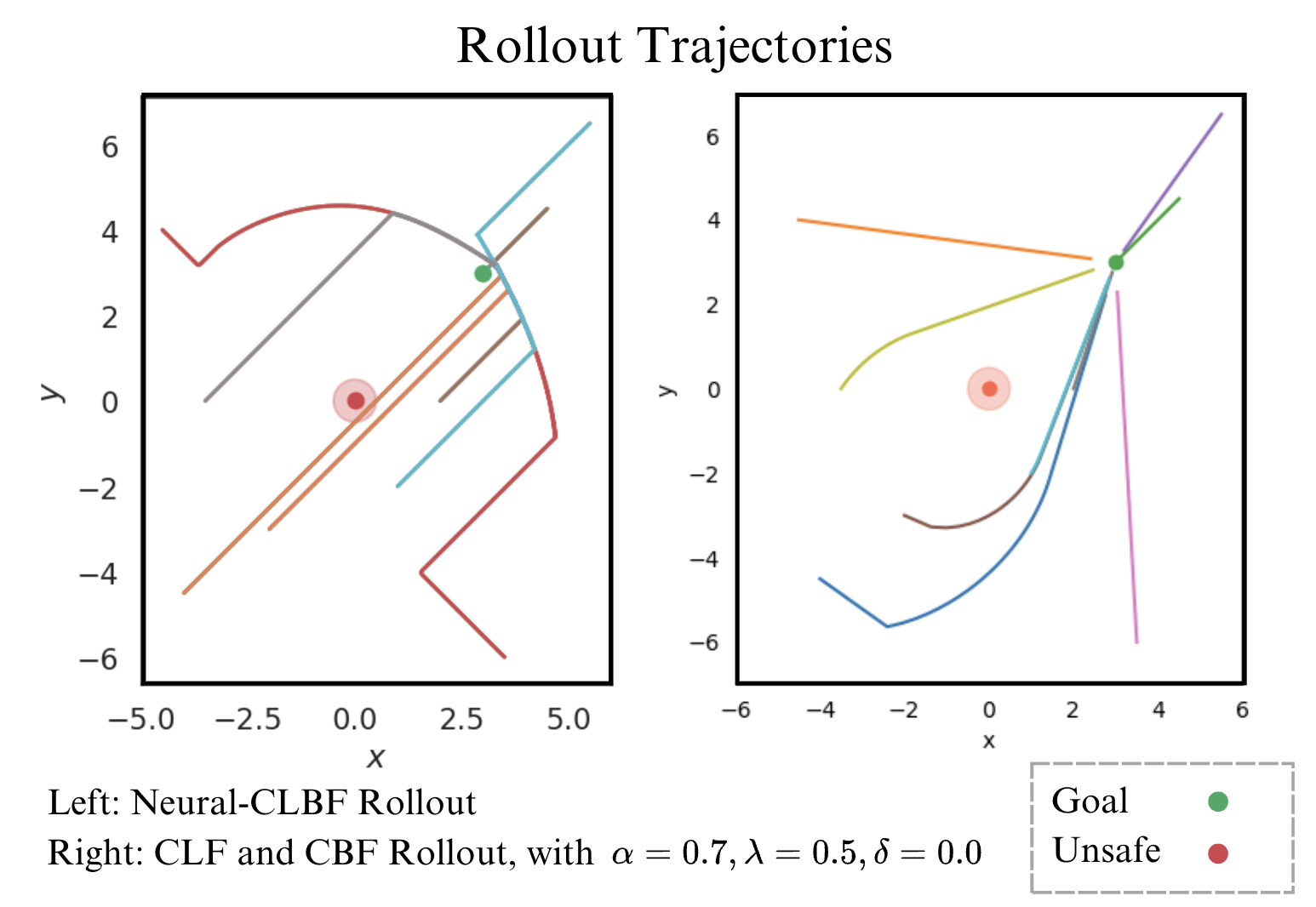
Safety and stability are common control requirements for affine-control systems. To check if a potential controller is feasible in ensuring stability and safety, the control Lyapunov function(CLF) and the control Barrier function(CBF) are usually used respectively. However, it is still difficult to design a stable and safe controller for nonlinear and uncertain systems, such as controlling a stratospheric balloon within a wind field with reach-avoid objective. Hence, we are interested in investigating if a model-based learning approach (neural clbf) can synthesize robust and feasible feedback controllers for this underactuated control system. Results show that neural clbf can achieve a better performance in a simple wind-driven system, but more model design revisions are needed to be taken into considerations.
> Show more
Dynamic Safety Shielding for Reinforcement Learning in Black-box
Environments
Independent
Advised by Prof. Hadas Kress-Gazit
Shielding, Automata Learning, Reinforcement Learning
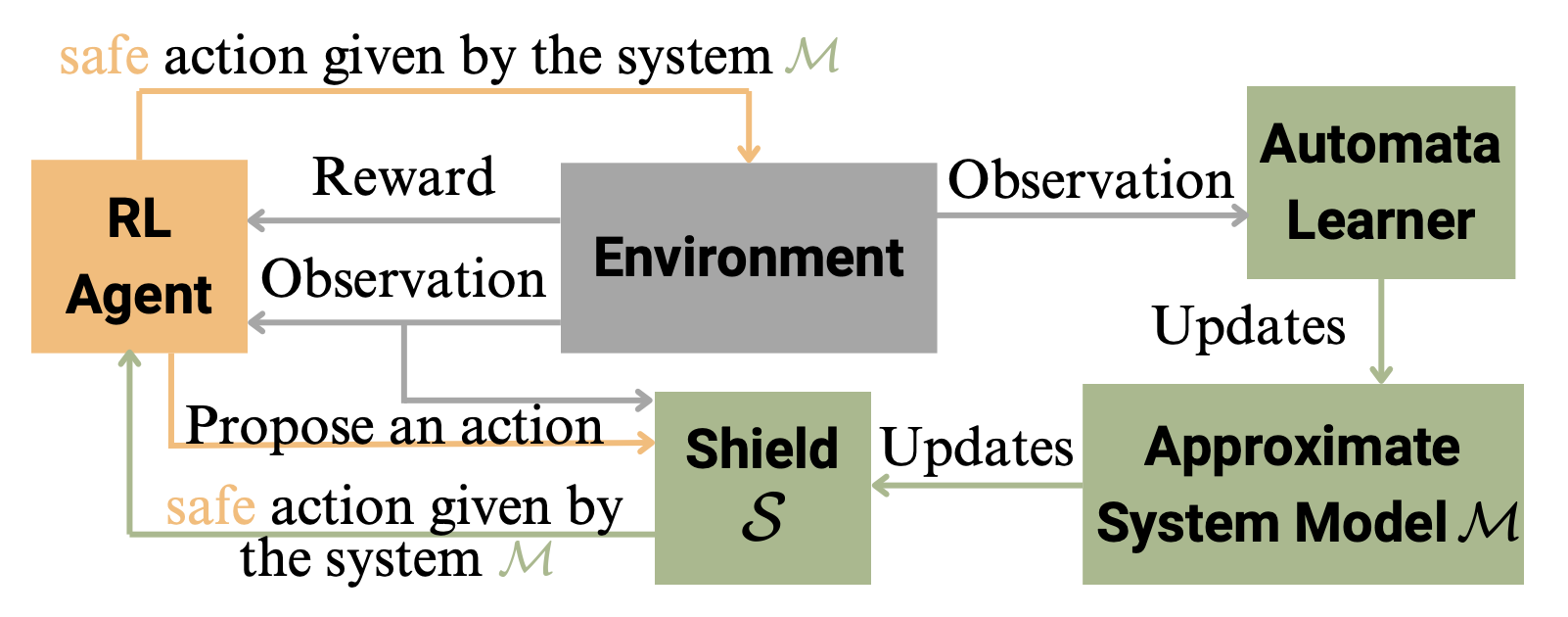
Reinforcement Learning (RL) algorithms aim to compute policies that maximize reward without
necessarily guaranteeing safety during learning or execution. This makes it challenging to use
RL in cyber-physical systems such as robotics, where unsafe actions may damage the robot and/or its
environment. In contrast to most previous studies that propose techniques to reduce the number
of unsafe actions given some prior knowledge of the environment, we are interested in the situation
where undesired behaviors can be reduced without any prior system knowledge. Hence, in this
study, we aim to explore a dynamic shielding technique that safeguards RL. Specifically, we implement a
variant of RPNI, a type of automata learning, which is constructed in parallel with the
model-based RL to filter out potential unsafe behaviors during action execution before the agent actually
experiences it. Our experiment shows that the number of undesired trials can be effectively
reduced compared to unshielded RL.
> Show more
Continuous Execution of High-level Collaborative Tasks for Heterogeneous
Robot Teams
Group
Advised by Prof. Hadas Kress-Gazit
Formal Synthesis, Multi-Robot Communication
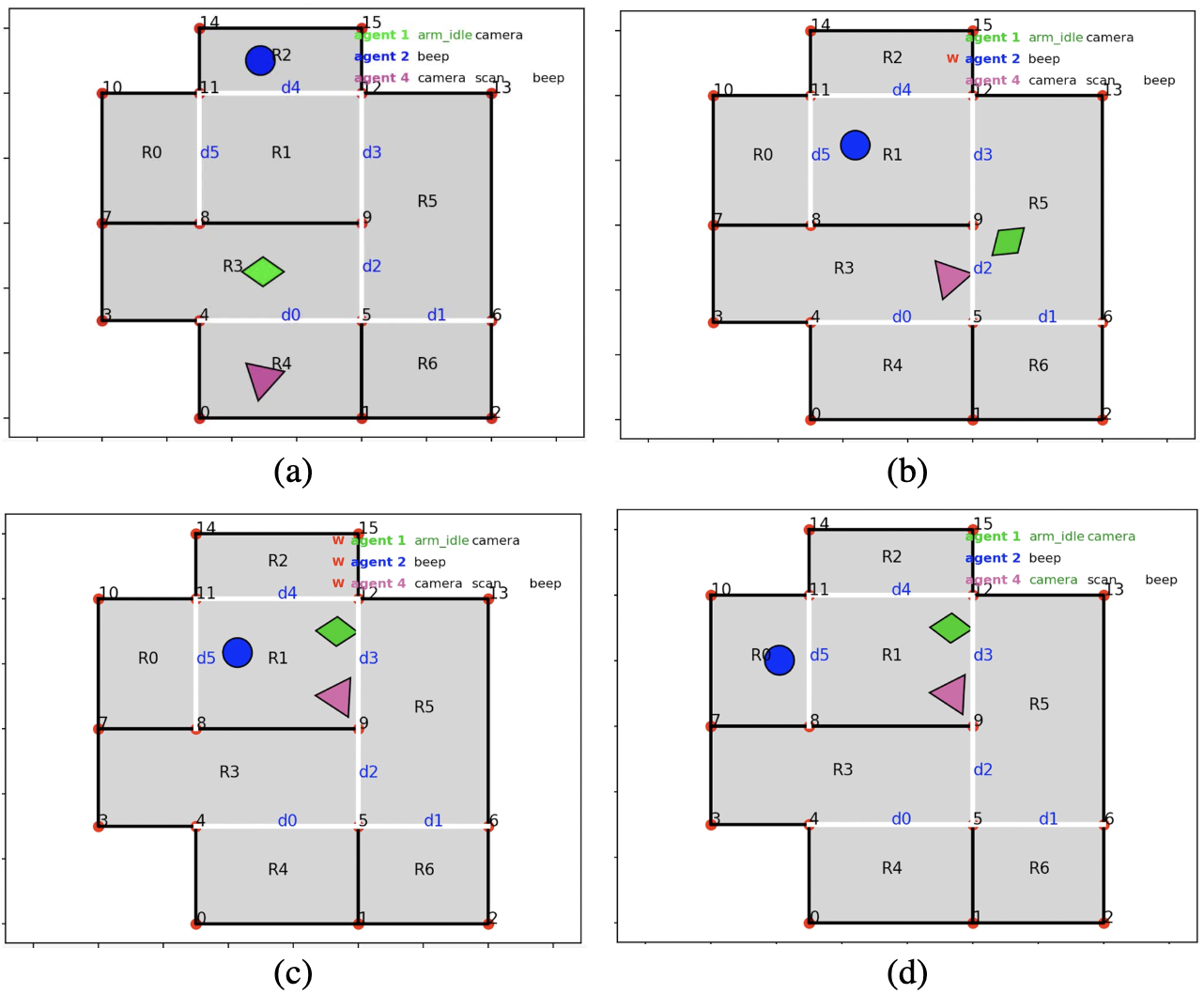
We propose a control synthesis framework for a heterogeneous multi-robot system to satisfy
collaborative tasks, where actions may take varying duration of time to complete. We encode
tasks
using the discrete logic \( \text{LTL}^\psi \), which uses the concept of bindings to interleave
robot actions
and express information about relationship between specific task requirements and robot
assignments.
We present a synthesis approach to automatically generate a teaming assignment and corresponding
discrete behavior that is correct-by-construction for continuous execution, while also
implementing
synchronization policies to ensure collaborative portions of the task are satisfied. We
demonstrate
our approach on a physical multi-robot system.
> Show more
Preference-Informed Whole-arm Manipulation for Physical Human-Robot
Interaction
Group
Advised by Prof. Tapomayukh Bhattacharjee
Operational Space Control, Preference Learning, pHRI
Robot caregiving tasks such as bathing, dressing, and transferring may require a robot arm to make contact with a human body at multiple points—not just at the robot's gripper or end effector. However, whole-arm contact presents challenges because varying human contact preferences may lead to unsafe or uncomfortable interactions. To address these challenges, we propose a novel algorithm that employs a conditional contextual bandit approach to distill user contact preferences into low-level pose and force control policies via a hierarchical operational space controller. Our approach intends to enable complex ma- nipulation tasks involving whole-arm contacts around humans, while adapting to contact preferences and maintaining control priorities. We propose a simulation-in-the-loop approach to minimize discomfort during preference learning, first gathering real-world feedback and then simulating further interactions in a digital twin environment. The robot refines its control policy iteratively in simulation, ensuring safe adaptation without direct experimentation on users until convergence. We perform a user study to develop a better understanding of contact preferences associated with physical robotic assistance and use the findings to initialize a realistic user model for our experiments. We validate our framework through a simulated bed-bathing task to demonstrate utility in caregiving. Results show that our framework effectively adapts to individual contact-related preferences while ensuring task completion and enhancing user comfort and safety during physical interactions.
> Show more
